
1. Discrete Fourier analysis
Today, I state a theorem. This afternoon, Mossel explains how harmonic analysis can be used in combinatorics. The Parseval identity, though elementary, turns out to be very powerful. Tomorrow, I will give an additional ingredient, hypercontractivity.
1.1. Collective coin flipping
In 1985, Ben Or and Linial discussed a problem coming from theoretical computer science called collective coin flipping. When designing algorithms, use of random bits helps a lot. One is satisfied if the algorithm gives a correct answer with probability 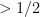
Even earlier, randomization arose in distributed computing. Synchronizing a large number of computers is uneasy. Assume 
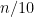
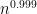
1.2. Boolean functions
Definition 1 A Boolean function is a function
(sometimes, we replace
with
).
Here is the procedure proposed by Ben Or and Linial: Processor 


Suggestion: Why not select at random a processor and take its bit ? Answer: We are not allowed to do this, since we are not allowed external random bits. All the randomness available belongs to individual processors.
Here are examples of Boolean functions.
- OR (resp. AND) function
(resp.
) do not produce a uniformly distributed bit.
- Dictatorship
does not do the job, since one bad processor can spoil it.
- Parity
mod
does not do well either, since every processor can change the output.
- Majority
if
,
otherwise. This can be spoiled by
bad processors with high probability. Indeed, the fluctuations of
are of size
Can one do better ? Yes, this is what Ben Or and Linial observed. Before, I introduce influence.
1.3. Influence
Definition 2 (Influence) Let
be a Boolean function. Assume that
(usually,
). Let
be a set of processors. The influence of
The influence of
The influence of
It is between 0 and 1.

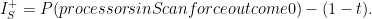
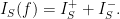
In case 


Define total influence as the sum of all 
Theorem 3 (Ben Or, Linial) : For all Boolean
, the total influence
In particular,
.

They realized that this is related to discrete isoperimetry (
- What can one say of the maximum influence ?
- Or more generally, of
, especially when
?
Ben Or and Linial found Boolean functions that do better than majority for collective coin tossing.
The first example is recursive majority on triples. Let us assume that 


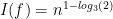
Later on, they found a better example: tribes. Let us assume that 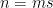




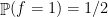
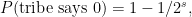
so
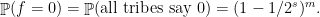
In this example, for all

so
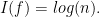
Note the asymmetry: to force outcome 0, one needs to put an adversarial voter in each of 

1.4. The KKL Theorem
Ben Or and Linial conjectured that one cannot do better, i.e. for every balanced Boolean function, there is a processor whose influence is at least
Theorem 4 (Kahn, Kalai, Linial) For every Boolean function
,

Proof given tomorrow. It relies on some Fourier analysis, plus hypercontractivity (Bonami, Beckner, Gross). We tried many other ideas which turned out to be useless.
Corollary 5 Presence of
adversaries will fool every Boolean function.
Are there better protocols than a single Boolean function ? Answer is Yes.
The first example is passing the baton. Let the first processor select at random a second processor, which selects at random a third processor, and so on. Use the random bit proposed by the winner, the last remaining processor. This takes 

N. Alon and M. Naor found a protocol with a smaller number of rounds.
Today’s record (U. Feige): Number of rounds is 
2. What is discrete harmonic analysis good for ?
Here is a list of questions to which the methods of discrete harmonic analysis are relevant.
2.1. Extremal combinatorics
Here are two sample results.
Sperner’s theorem (1928): An antichain of subsets of an 

Erdös-Ko-Rado theorem (1935): If F is a collection of 

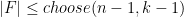

- Question: What happens in case equality almost holds? e.g. if we assume
,
a small constant ?
- Question: How many large antichains are there ?
- Question: What if we replace pairwise non disjoint with 3-wise non disjoint ?
These questions seem to be substantially harder.
2.2. Random graphs
Subject started by Erdös and Renyi in the 1960’s. Here is a model which slightly differs from theirs, but is easier to analyze.
Given an 

Given a finite graph 
2.3. Percolation and related models
Start with 

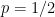
- For
, subgraph has only small connected components.
- For
- For
, this occurs with probability 1.
Every graph property (connectedness, simply connectedness,…) is 1 or 0 depending on the assignments associated to edges (open or closed), i.e. a Boolean function.
2.4. Computational complexity
Given a Boolean function
N/NP can be formulated as follows. The existence of a Hamiltonian cycle in an
Bounding from below circuit complexity has shown to be very hard. Existing results apply only to very limited submodels. For instance, for bounded depths circuits, discrete harmonic methods are relevant.
